Parallelism
Difference between SMP, SPMD, and HMPP?
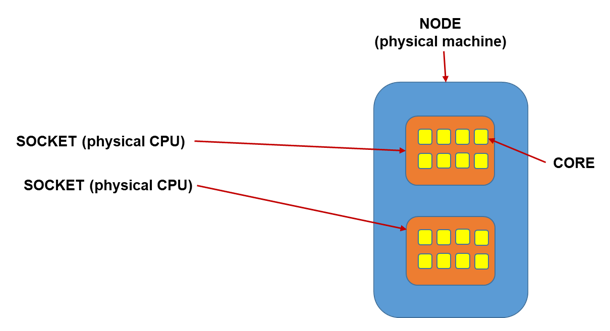
Figure 1. Computer Cluster Node Example
- SMP (Shared Memory Parallelism) solution
With SMP, the CAE Model is solved as 1 domain. Multiple threads are used in one domain to solve the problem. One thread per core is used in the problem solution. This method is only efficient for a low number of core (<8) and only a single node can be used. To solve a simulation using 1 domain with 8 threads on 8 cores, the submission option
-np1-nt8 would be used.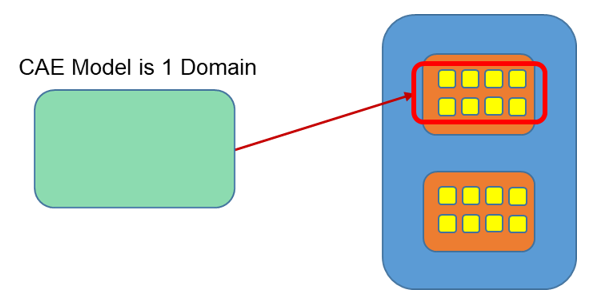
Figure 2. - SPMD (Single Program Multiple Data) solution With SPMD, the CAE Model is split into many domains. Each domain is solved by one core so only 1 thread is used per domain. Many nodes can be used to solve the problem. Radioss uses MPI (message passing interface) software to communicate information between domains. This method is efficient up to 256 cores when the nodes are connected with high-speed interconnection networks. The SPMD version can run on distributed memory machines, shared memory machines, workstations cluster or high performance computation cluster. In the following example, the model is split into 32 domains and solved using 2 nodes with 2 CPU per node and each CPU has 8 cores. To solve a simulation using 32 domains on 32 cores, the submission option
-np32-nt1 would be used.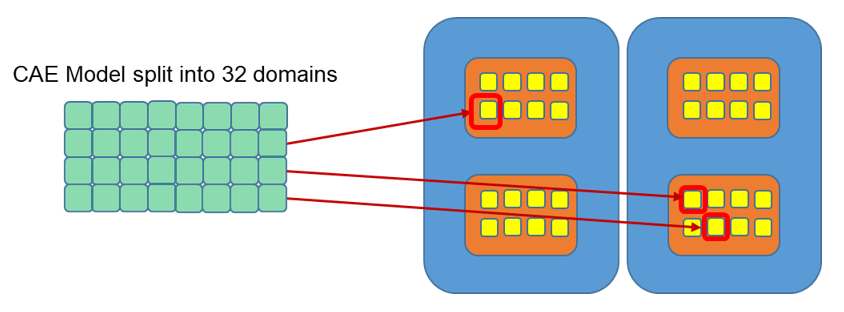
Figure 3. - HMPP (Hybrid Massively Parallel Processing) solution
With HMPP, the CAE Model is split into several domains. Each domain is solved by multiple cores. Within each domain, multiple threads are used to solve the problem. Each thread uses 1 core. Radioss uses MPI software to communicate information between domains. Multiple nodes can be used to solve the problem. Since there are fewer domains, there is less communication between the domains, so this method can be useful if a large number of cores (>256 cores) are used to solve a problem. It is also useful if the network connection is slow between the nodes
The communication between the threads in one domain is most efficient if all the threads are on the same CPU. In this example, the same 2 nodes with 2 CPU per node and 8 cores per CPU solves the problem. The model is split into 4 domains with each domain using 8 threads for a total of 32 cores used. In this case, the submission option-np4-nt8 would be used.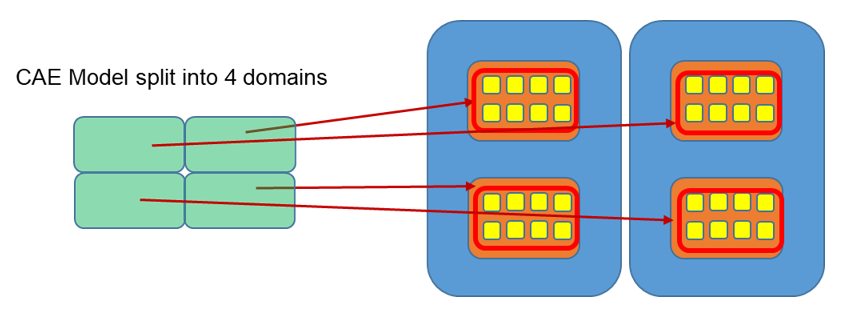
Figure 4.
What is /PARITH/ON?
The option “Parallel Arithmetic” is a key differentiator of Radioss and other explicit solvers. It is available for Radioss SMP, SPMD, and HMPP versions.
For a Radioss release and computer architecture, the parallel arithmetic option guarantees that identical results are obtained regardless of the number of processors used to solve the problem.
“Parallel Arithmetic” reduces the sensitivity of an explicit simulations, especially since these simulations naturally imply a lot of local buckling situations.
“Parallel Arithmetic” is not guaranteed in models with Incompatible Kinematic Conditions.