Hybrid Shared/Distributed Memory Parallelization (SPMD)
Single Program, Multiple Data (SPMD) is a parallelization technique in computing that is employed to achieve faster results by splitting the program into multiple subsets and running them simultaneously on multiple processors/machines.
| Application | Version | Supported Platforms | MPI |
|---|---|---|---|
| OptiStruct SPMD | 2021 | Linux 64 bit | IBM Platform MPI 9.1.2 (formerly HP-MPI) or Intel MPI - Version 2018 Update 4 (recommended) |
| Windows 64 bit | IBM Platform MPI 9.1.2 (formerly HP-MPI) or Intel MPI - 5.1.0.078 (recommended) |
Domain Decomposition Method
Domain Decomposition Method (DDM) is available for analysis and optimization. DDM is a parallelization option in OptiStruct that can help significantly reduce model runtime with improved scalability compared to legacy shared memory parallelization approaches, especially on machines with a high number of cores (for example, greater than 8).
DDM allows two main levels of parallelization depending on the attributes of the model.
DDM Level 1 – Task-based parallelization
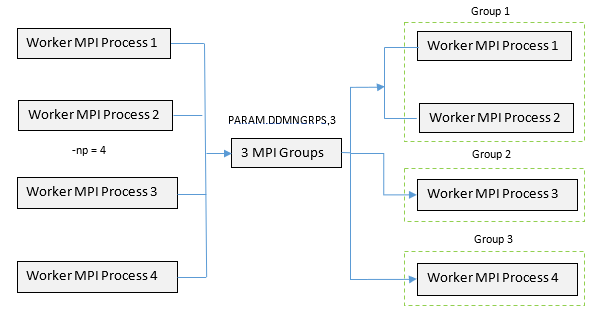
Figure 1. Example DDM Setup with Four MPI Processes (
-np=4) which are divided into 3 groups. This is an example of how grouping can be accomplished to parallelize a
model with multiple parallelizable tasks in DDM Level 1| Supported Solutions | Task-based Parallelizable Entities in DDM | Non-Parallelizable Tasks |
|---|---|---|
| Linear Static Analysis | √ Two or more static Boundary Conditions are parallelized
(Matrix Factorization is the step that is parallelized since it
is computationally intensive). √ Sensitivities are parallelized for Optimization. |
√ Iterative Solution is not parallelized. (Only Direct Solution is parallelized). |
| Nonlinear Static Analysis | √ Two or more Nonlinear Static Subcases are parallelized. | See Note 1 √ Optimization is not parallelized. |
| Buckling Analysis | √ Two or more Buckling Subcases are parallelized. √ Sensitivities are parallelized for Optimization. |
|
| Direct Frequency Response Analysis | √ Loading Frequencies are parallelized. | √ Optimization is not parallelized. |
| Modal Frequency Response Analysis | √ Different modal Spaces are parallelized. | √ Optimization is not parallelized. |
| DGLOBAL Global Search Optimization with multiple starting points | √ Starting Points are parallelized. | |
| Multi-Model Optimization | √ Models listed in the main file are parallelized depending
on the number of specified -np overall and/or
the number of -np defined for each model in the
main file. |
√ Task-based parallelization is not applicable within each MMO model. Only Geometric partitioning (DDM level 2) is conducted for each individual model in MMO. |
- For Nonlinear
Static Analysis, Level 1 DDM (Task-based Distribution) is:
- Supported for both Small Displacement and Large Displacement Nonlinear Static Analysis.
- Is not active by default, and can be activated by using
PARAM,DDMNGRPS or
-ddmngrpsrun option. For other supported solutions above, multi-level DDM is active by default. - If a single nonlinear pretensioning subcase exists, then all other nonlinear subcases should be part of the same pretensioning chain; otherwise, the run will switch to regular DDM.
- Nonlinear Transient Analysis is currently not supported.
- Example setup for Nonlinear Static for multi-level
DDM: Every subcase in the examples below is a Nonlinear Static subcase (NLSTAT) Supported setup – Example 1:
SUBCASE 1 PRETENSION=5 SUBCASE 2 PRETENSION=6 STATSUB(PRETENS)=1 CNTNLSUB=1 SUBCASE 3 STATSUB(PRETENS)=2 CNTNLSUB=2 SUBCASE 4 STATSUB(PRETENS)=2 CNTNLSUB=2If PARAM, DDMNGRPS, 2 is specified, then Subcases 1 and 2 will be run first with regular DDM geometric partitioning only, and subsequently Subcases 3 and 4 will be run in parallel with multi-level task-based DDM.
Supported setup - Example 2:SUBCASE 1 PRETENSION=5 SUBCASE 2 STATSUB(PRETENS)=1 CNTNLSUB=1 SUBCASE 3 STATSUB(PRETENS)=1 CNTNLSUB=1If PARAM, DDMNGRPS, 2 is specified, then Subcase 1 will be run first with regular DDM geometric partitioning only, and subsequently Subcases 2 and 3 will be run in parallel with multi-level task-based DDM.
Supported setup - Example 3:SUBCASE 1 NLPARM = 1 SUBCASE 2 NLPARM = 1If PARAM, DDMNGRPS, 2 is specified, then Subcases 1 and 2 will be run in parallel with multi-level task-based DDM.
Unsupported setup – Example 4:SUBCASE 1 PRETENSION=5 SUBCASE 2 PRETENSION=6 STATSUB(PRETENS)=1 CNTNLSUB=1 SUBCASE 3 STATSUB(PRETENS)=2 CNTNLSUB=2This is not supported in multi-level DDM. Even if PARAM, DDMNGRPS, 2 is specified, OptiStruct switches to regular DDM.
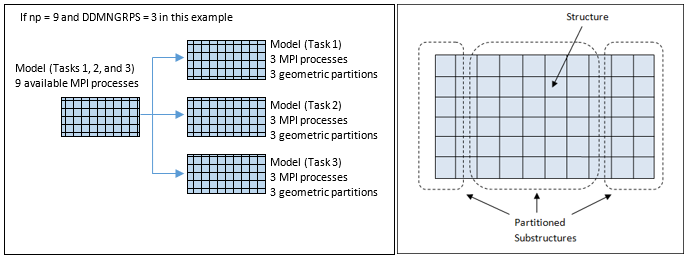
Figure 2. (a) DDM Level 1: Parallelization of Tasks; (b) DDM Level 2: Geometric Partitioning of each Task-based Models. depending on the number of MPI processes and number of MPI groups
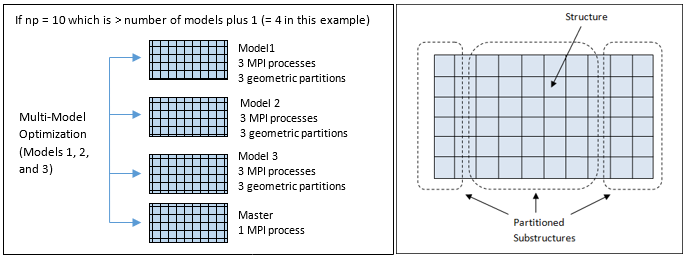
Figure 3. (a) DDM Level 1: Parallelization of MMO Models; (b) DDM Level 2: Geometric Partitioning of Some or all of the MMO Optimization Models. depending on the number of MPI processes and number of MPI groups
DDM Level 2 – Parallelization of Geometric Partitions
The second level of parallelization occurs at the distributed task level. Each distributed task can be further parallelized via Geometric partitioning of the model. These geometric partitions are generated and assigned depending on the number of MPI groups and the number of MPI processes in each group.
The second level DDM process utilizes graph partition algorithms to automatically partition the geometric structure into multiple domains (equal to the number of MPI processes in the corresponding group). During FEA analysis/optimization, an individual domain/MPI process only processes its domain related calculations. Such procedures include element matrix assembly, linear solution, stress calculations, sensitivity calculations, and so on.
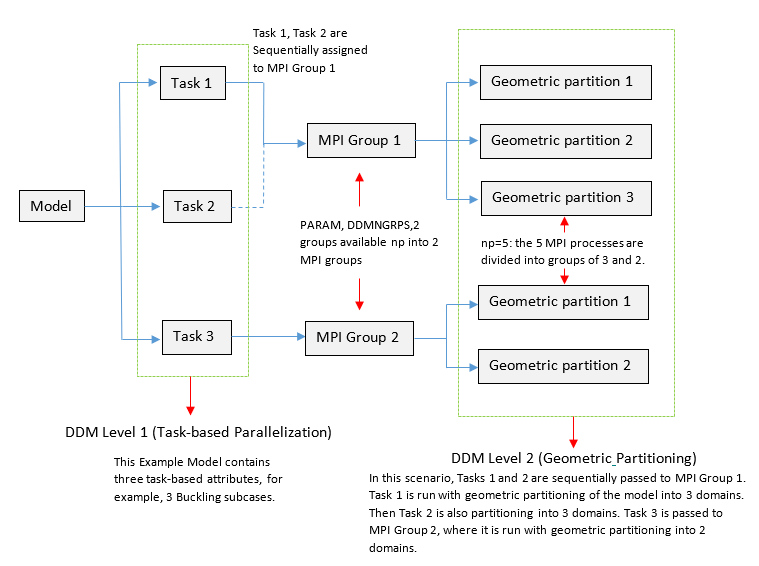
Figure 4. Example DDM Setup with 5 MPI Processes (
-np=5) . The model has 3 task attributes (Example, 3 buckling subcases, or 3
DFREQ loading frequencies, etc). PARAM,
DDMNGRPS,2 is defined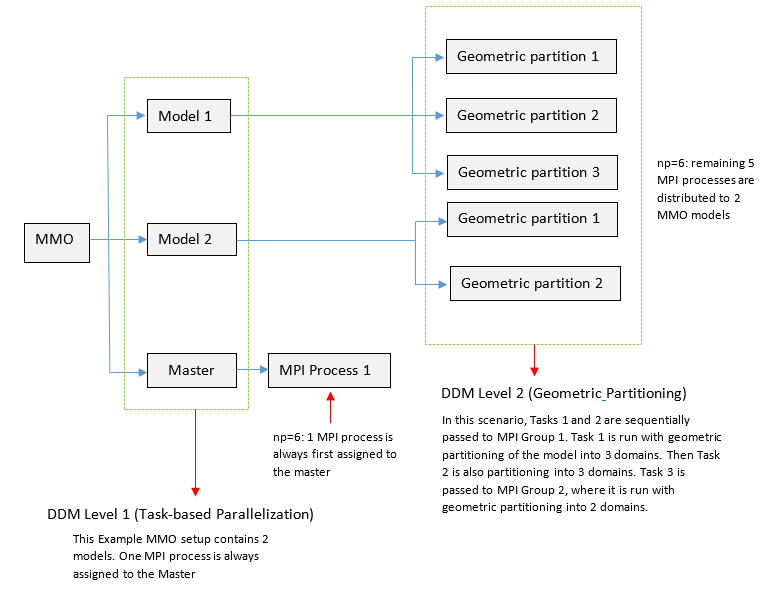
Figure 5. Example DDM Setup with 6 MPI Processes (
-np=6). The MMO setup has 2 models. PARAM,DDMNGRPS should not
be used in conjunction with MMOThe DDM functionality for level two parallelization is direct geometric partitioning of a model based on the number of MPI processes available in the MPI group that is assigned to this task.
DDM level 2 is purely geometric partitioning and you can enforce only level 2 DDM by setting PARAM,DDMNGRPS,MIN. This minimizes the number of groups that can be assigned for the specified model, thereby leading to a pure geometric partitioning parallelization.
Hybrid DDM parallelization using both Level 1 and Level 2 parallelization is possible
by setting
PARAM,DDMNGRPS,AUTO or
PARAM,DDMNGRPS,#, where
# is the number of MPI groups. In case of
AUTO, which is also the default for any DDM run, OptiStruct heuristically assigns the number of MPI groups for
a particular model, depending on model attributes and specified
-np.
-np and the number of MPI groups.
PARAM,DDMNGRPS,<ngrps>
is an optional parameter and AUTO is always the default for any DDM
run. The model is first divided into parallelizable tasks/starting points (refer to
Table 2 for supported solution sequences for level 1).
Each task/starting point is then solved sequentially by an MPI group. Each MPI group
consists of one or more MPI Processes. If an MPI group consists of multiple MPI
processes, then the task/starting point is solved by geometric partitioning in that
MPI group (the number of MPI processes in a group is equal to the number of
geometric partitions. Refer to Supported Solution Sequences for DDM Level 2 Parallelization (Geometric Partitioning) for solutions that
support geometric partitioning level 2 DDM).- In the case of Global Search Option, the MPI process groups should not be confused with the number of groups (NGROUP) on the DGLOBAL entry. They are completely different entities and do not relate to one another.
- In the case of Global Search Option, each MPI process prints the detailed report of the starting points processed and the summary is output in the .out file of the main process. The naming scheme of the generated folders is similar to the serial GSO approach (each folder ends with _SP#_UD#, identifying the Starting Point and Unique Design numbers).
- PARAM,DDMNGRPS should not be used
in conjunction with Multi-Model Optimization (MMO) runs. For MMO, DDM
level 1 (task-based parallelization) is automatically activated when
specified np is greater than number of models plus 1 (or if number of
npfor each model is explicitly defined in the main file). DDM Level 1 for MMO simply distributes the extra MPI processes to models evenly. DDM Level 2 parallelization is geometric partitioning of each model based on the number of MPI processes assigned to each one. For more information, refer to Multi-Model Optimization.
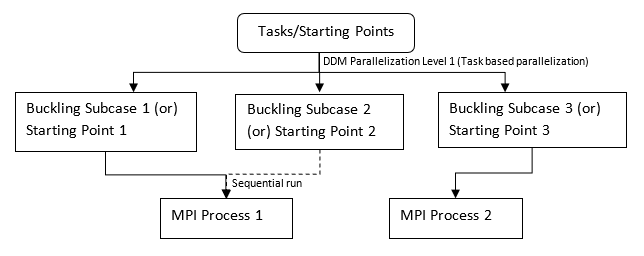
Figure 6. Example of 3 Buckling Subcase Model (or 3 Starting Points in DGLOBAL). First Level of DDM Parallelization:
-np 2
-ddm with
PARAM,DDMNGRPS,MAX
(assign geometric partitions/starting points to DDM MPI processes,
sequentially)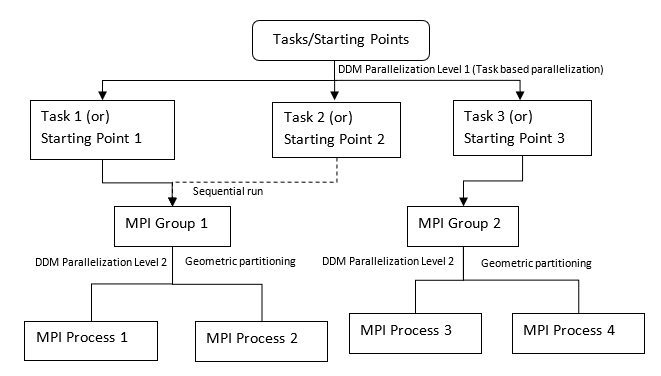
Figure 7. Example of 3 Buckling Subcase Model (or 3 Starting Points in DGLOBAL). Hybrid DDM with 2 Levels of Parallelization
-np 4
-ddm, and
PARAM,DDMNGRPS,2
(assigns 3 Buckling subcases/starting points to DDM MPI groups,
sequentially. Subsequently, geometric partitioning is done within each MPI | Solution | Activation | Level 1 | Level 2 | Grouping |
|---|---|---|---|---|
| Parallel Global Search Option (DDM) | Use -np # -ddmDefault is Hybrid DDM with PARAM,DDMNGRPS,AUTO PARAM,DDMNGRPS,<ngrps> is optional |
Starting points are parallelized (each starting point is solved sequentially in a MPI process, if multiple starting points are assigned to 1 MPI process). | A Starting point is geometrically partitioned and solved in parallel by an MPI group (if the MPI group contains multiple MPI processes). | Grouping via
PARAM,DDMNGRPS,AUTO
is the default. If you need to adjust number of MPI groups, use
PARAM,DDMNGRPS,<ngrps>
(if np> ngrps then this activates 2nd level
parallelization wherein geometric partitioning of some/all
starting point run(s) occurs when multiple MPI processes can
operate on a single starting point). |
| General Analysis/Optimization runs (DDM) | Use -np # -ddmDefault is Hybrid DDM with PARAM,DDMNGRPS,AUTO. PARAM,DDMNGRPS,<ngrps> is optional. |
Loadcases, loading Frequencies (Task-based parallelization) Refer to Table 2 for supported solutions). | Each loadcase/loading frequency is geometrically partitioned and solved in parallel by an MPI group (if the MPI group contains multiple MPI processes). | Grouping via
PARAM,DDMNGRPS,AUTO
is the default. If you need to adjust number of MPI groups, use
PARAM,DDMNGRPS,<ngrps> Like
the above scenario, if |
| Multi-Model Optimization (MMO) with DDM | Use -np #
-mmoPARAM,DDMNGRPS is not supported with MMO |
Optimization models are parallelized wherein extra MPI
processes (> no of models plus 1) are distributed evenly to
models in mainr MMO file (or user- defined -np
for each model in main file). |
Any MMO optimization model is geometrically partitioned and solved in parallel (number of partitions depends on number of MPI processes/np assigned to it). | There is no grouping via PARAM,DDMNGRPS as it is not supported for MMO. However, grouping is indirectly accomplished by automatic distribution of np to the MMO models or by explicit user input via Main file. |
Supported Solution Sequences for DDM Level 2 Parallelization (Geometric Partitioning)
| DDM Level | Supported Solutions | ||
|---|---|---|---|
| Domain Decomposition (Level 2) | Linear Static Analysis and Optimization | Nonlinear Static analysis | Linear Buckling Analysis and Optimization (MUMPS is available for SMP) |
| Fatigue Analysis (based on Linear Static, Modal Transient, Random Response) | Normal Modes (with Lanczos) | Modal Frequency Response (with Lanczos) | |
| Preloaded Modal Frequency Response (with AMLS/AMSES) Only preloading static subcase is parallelized. |
Nonlinear Transient Analysis | Direct Linear Transient Analysis | |
| Modal Linear Transient Analysis | Structural Fluid Structure Interaction (Structural FSI) | Multi-Model Optimization (MMO) | |
| Direct Frequency Response Analysis (Structural, Acoustic, and MFLUID) (MUMPS is available for SMP) | Nonlinear Steady-State Heat Transfer Analysis | Nonlinear Transient Heat Transfer Analysis | |
| Periodic Boundary Conditions (PERBC) | |||
Iterative solver are currently not supported in conjunction with DDM.
- The
-ddmrun option can be used to activate DDM. Refer to How many MPI processes (-np) and threads (-nt) per MPI process should I use for DDM runs? for information on launching Domain Decomposition in OptiStruct. - In DDM mode, there is no distinction between MPI process types (for
example, manager, main, secondary, and so on). All MPI processes
(domains) are considered as worker MPI processes. Additionally, hybrid
DDM with multiple levels is the default for any DDM run. Therefore, if
-np nis specified, OptiStruct first divides available-npinto MPI groups heuristically (PARAM,DDMNGRPS,AUTO) and then within each MPI group, subsequent geometric partitions are conducted wherein the number of such partitions in each group are equal to the number of MPI processes available in that group. These MPI processes are then run on corresponding sockets/machines depending on availability. - Hybrid computation is supported.
-ntcan be used to specify the number of threads (m) per MPI process in an SMP run. Sometimes, hybrid performance may be better than pure MPI or pure SMP mode, especially for blocky structures. It is also recommended that the total number of threads for all MPI processes (n x m) should not exceed the number of physical cores of the machine.
Known Issues
MPI run on Linux may error out due to an
ssh error.
Error :/bin/ssh:
$ALTAIR_HOME/altair/hwsolvers/common/python/python3.5/linux64/lib/libcrypto.so.10:
version OPENSSL_1.0.2 not found (required by /bin/ssh)This can occur when the libcrypto library from Python conflicts with
the one required by MPI. To resolve this, copy libcrypto from the
system to the location mentioned in the error above. In the system, this library is
typically in /usr/lib64.
Launch OptiStruct DDM
There are several ways to launch parallel programs with OptiStruct DDM.
Remember to propagate environment variables when launching OptiStruct DDM, if needed (this is typically only required if running the OptiStruct executable directly, instead of the OptiStruct script/GUI). Refer to the respective MPI vendor’s manual for more details. In OptiStruct, commonly used MPI runtime software are automatically included as a part of the HyperWorks installation. The various MPI installations are located at $ALTAIR_HOME/mpi.
Linux Machines
Using OptiStruct Scripts
Domain Decomposition Method (DDM)
[optistruct@host1~]$ $ALTAIR_HOME/scripts/optistruct –mpi [MPI_TYPE] –ddm -np
[n] -cores [c] [INPUTDECK] [OS_ARGS]
Where, -mpi: optional run option to select the MPI implementation
used:
[MPI_TYPE] can be:- pl
- For IBM Platform-MPI (Formerly HP-MPI)
- i
- For Intel MPI
-ddm- Optional parallelization type selector that activates DDM (DDM is the default)
-np- Optional run option to identify the total number of MPI processes for the run
[n]- Integer value specifying the number of total MPI processes
(
-np) -cores- Optional run option to identify the number of total cores
(
-np*-nt) for the run [c]- Integer value specifying the number of total cores
(
-cores) [INPUTDECK]- Input deck file name
[OS_ARGS]- Lists the arguments to OptiStruct (Optional, refer to Run Options for further information).
- Adding the command line option
-testmpi, runs a small program which verifies whether your MPI installation, setup, library paths and so on are accurate. - OptiStruct DDM can also be launched using the Compute Console (ACC) GUI. (Refer to Compute Console (ACC)).
- Though it is not recommended, it is also possible to launch OptiStruct DDM without the GUI/ Solver Scripts. Refer to How many MPI processes (-np) and threads (-nt) per MPI process should I use for DDM runs? in the FAQ section.
- Adding the optional command line option
-mpipath PATHhelps you find the MPI installation if it is not included in the current search path or when multiple MPI's are installed. - If an SPMD run option (
-mmo/-ddm/-fso) is not specified, DDM is run by default.
Windows Machines
Using OptiStruct Scripts
Domain Decomposition Method (DDM)
[optistruct@host1~]$ $ALTAIR_HOME/hwsolvers/scripts/optistruct.bat –mpi
[MPI_TYPE] –ddm -np [n] -cores [c] [INPUTDECK] [OS_ARGS]
Where, -mpi: optional run option to select the MPI implementation
used.
[MPI_TYPE] can be:- pl
- For IBM Platform-MPI (Formerly HP-MPI)
- i
- For Intel MPI
-ddm- Optional parallelization type selector that activates DDM (DDM is the default)
-np- Optional run option to identify the total number of MPI processes for the run
[n]- Integer value specifying the number of total MPI processes
(
-np) -cores- Optional run option to identify the number of total cores
(
-np*-nt) for the run [c]- Integer value specifying the number of total cores
(
-cores) [INPUTDECK]- Input deck file name
[OS_ARGS]- Lists the arguments to OptiStruct (Optional, refer to Run Options for further information).
- Adding the command line option
-testmpi, runs a small program which verifies whether your MPI installation, setup, library paths and so on are accurate. - OptiStruct DDM can also be launched using the Compute Console (ACC) GUI. (Refer to Compute Console (ACC)).
- It is also possible to launch OptiStruct DDM without the GUI/ Solver Scripts. (Refer to How many MPI processes (-np) and threads (-nt) per MPI process should I use for DDM runs? in the FAQ section.
- Adding the optional command line option
-mpipath PATHhelps you find the MPI installation if it is not included in the current search path or when multiple MPI's are installed. - If a SPMD run option (
-mmo/ -ddm /-fso) is not specified, DDM is run by default.
Linux Machines using Direct Calls to Executables
It is recommended to use the OptiStruct script
($ALTAIR_HOME/scripts/optistruct) or the OptiStruct GUI (Compute Console (ACC)) instead of directly running the OptiStruct executable. However, if directly using the executable is
unavoidable for a particular run, then it is important to first define the corresponding
environment variables, RADFLEX license environment variables, library path variables and so on
before the run.
On a Single Host (for IBM Platform-MPI and Intel MPI)
Domain Decomposition Method (DDM)
[optistruct@host1~]$ mpirun -np [n]
$ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd [INPUTDECK] [OS_ARGS]
-ddmmode
Multi-Model Optimization (MMO)
[optistruct@host1~]$ mpirun -np [n]
$ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd [INPUTDECK] [OS_ARGS]
-mmomode
Failsafe Topology Optimization (FSO)
[optistruct@host1~]$ mpirun -np [n]
$ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd [INPUTDECK] [OS_ARGS]
-fsomode
- optistruct_spmd
- The OptiStruct SPMD binary
[n]- Number of processors
[INPUTDECK]- Input deck file name
[OS_ARGS]- Lists the arguments to OptiStruct other than
-ddmmode/-mmomode/-fsomode(Optional, refer to Run Options for further information).Note: Running OptiStruct SPMD, using direct calls to the executable, requires an additional command-line option-ddmmode/-mmomode/-fsomode(as shown above). If one of these run options is not used, there will be no parallelization and the entire program will be run on each node.
On a Linux cluster (for IBM Platform-MPI)
Domain Decomposition Method (DDM)
[optistruct@host1~]$ mpirun –f [appfile]
Where, appfile contains:
optistruct@host1~]$ cat appfile
-h [host i] -np [n] $ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd
[INPUTDECK] -ddmmode
Multi-Model Optimization (MMO)
[optistruct@host1~]$ mpirun –f [appfile]
Where, appfile contains:
-h [host i] -np [n] $ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd
[INPUTDECK] -mmomode
Failsafe Topology Optimization (FSO)
[optistruct@host1~]$ mpirun –f [appfile]
Where, appfile contains:
-h [host i] -np [n] $ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd
[INPUTDECK] -fsomode
[appfile]- Text file which contains process counts and a list of programs
- optistruct_spmd
- OptiStruct SPMD binary
-ddmmode/-mmomode/-fsomode (as shown above). If one of these options is
not used, there will be no parallelization and the entire program will be run on each
node.c1 and
c2)[optistruct@host1~]$ cat appfile
-h c1 –np 2 $ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd [INPUTDECK] -ddmmode
-h c2 –np 2 $ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd [INPUTDECK] –ddmmodeOn a Linux cluster (for Intel-MPI)
Domain Decomposition Method (DDM)
[optistruct@host1~]$ mpirun –f [hostfile] -np [n]
$ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd [INPUTDECK] [OS_ARGS]
-ddmmode
Multi-Model Optimization (MMO)
[optistruct@host1~]$ mpirun –f [hostfile] -np [n]
$ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd [INPUTDECK] [OS_ARGS]
-mmomode
Failsafe Topology Optimization (FSO)
[optistruct@host1~]$ mpirun –f [hostfile] -np [n]
$ALTAIR_HOME/hwsolvers/optistruct/bin/linux64/optistruct_spmd [INPUTDECK] [OS_ARGS]
-fsomode
- optistruct_spmd
- OptiStruct SPMD binary
[hostfile]- Text file which contains the host names
[host i]- One host requires only one line.
- Running OptiStruct SPMD, using direct calls to the
executable, requires an additional command-line option
-ddmmode/-mmomode/-fsomode(as shown above). If one of these options is not used, there will be no parallelization and the entire program will be run on each node.
c1
and
c2)[optistruct@host1~]$ cat hostfile
c1
c2Windows Machines using Direct Calls to Executables
On a Single Host (for IBM Platform-MPI)
Domain Decomposition Method (DDM)
[optistruct@host1~]$ mpirun -np [n]
$ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] [OS_ARGS]
-ddmmode
Multi-Model Optimization (MMO)
[optistruct@host1~]$ mpirun -np [n]
$ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] [OS_ARGS]
-mmomode
Failsafe Topology Optimization (FSO)
[optistruct@host1~]$ mpirun -np [n]
$ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] [OS_ARGS]
-fsomode
- optistruct_spmd
- OptiStruct SPMD binary
[n]- Number of processors
[INPUTDECK]- Input deck file name
[OS_ARGS]- Lists the arguments to OptiStruct other than
-ddmmode/-mmomode/-fsomode(Optional, refer to Run Options for further information).Note: Running OptiStruct SPMD, using direct calls to the executable, requires an additional command-line option-ddmmode/-mmomode/-fsomode(as shown above). If one of these run options is not used, there will be no parallelization and the entire program will be run on each node.
On a Single Host (for Intel-MPI)
Domain Decomposition Method (DDM)
[optistruct@host1~]$ mpiexec -np [n]
$ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] [OS_ARGS]
-ddmmode
Multi-Model Optimization (MMO)
[optistruct@host1~]$ mpiexec -np [n]
$ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] [OS_ARGS]
-mmomode
Failsafe Topology Optimization (FSO)
optistruct@host1~]$ mpiexec -np [n]
$ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] [OS_ARGS]
-fsomode
- optistruct_spmd
- OptiStruct SPMD binary
[n]- Number of processors
[INPUTDECK]- Input deck file name
[OS_ARGS]- Lists the arguments to OptiStruct other than
-ddmmode/-mmomode/-fsomode(Optional, refer to Run Options for further information).
On Multiple Windows Hosts (for IBM Platform-MPI)
Domain Decomposition Method (DDM)
[optistruct@host1~]$ mpirun –f [hostfile]
Where, appfile contains:
optistruct@host1~]$ cat appfile
-h [host i] -np [n] $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd
[INPUTDECK] -ddmmode
Multi-Model Optimization (MMO)
[optistruct@host1~]$ mpirun –f [hostfile]
Where, appfile contains:
optistruct@host1~]$ cat appfile
-h [host i] -np [n] $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd
[INPUTDECK] -mmomode
Failsafe Topology Optimization (FSO)
[optistruct@host1~]$ mpirun –f [hostfile]
Where, appfile contains:
optistruct@host1~]$ cat appfile
-h [host i] -np [n] $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd
[INPUTDECK] -fsommode
[appfile] is the text file which contains process counts and a list
of programs.-ddmmode/-mmomode/-fsomode (as shown above). If one of these run
options is not used, there will be no parallelization and the entire program will be run
on each node.c1 and
c2)optistruct@host1~]$ cat hostfile
-host c1 –n 2 $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] -mpimode
-host c2 –n 2 $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] –mpimodeOn Multiple Windows Hosts (for Intel-MPI)
Domain Decomposition Method (DDM)
[optistruct@host1~]$ mpiexec –configfile [config_file]
Where, config_file contains:
optistruct@host1~]$ cat config_file
-host [host i] –n [np] $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd
[INPUTDECK] –ddmmode
Multi-Model Optimization (MMO)
[optistruct@host1~]$ mpiexec –configfile [config_file]
Where, config_file contains:
optistruct@host1~]$ cat config_file
-host [host i] –n [np] $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd
[INPUTDECK] -mmomode
Failsafe Topology Optimization (FSO)
[optistruct@host1~]$ mpiexec –configfile [config_file]
Where, config_file contains:
optistruct@host1~]$ cat config_file
-host [host i] –n [np] $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd
[INPUTDECK] -fso
[config_file] is the text file which contains the command for each host.- One host needs only one line.
- Running OptiStruct SPMD, using direct calls to the
executable, requires an additional command-line option
-ddmmode/-mmomode/-fsomode(as shown above). If one of these options is not used, there will be no parallelization and the entire program will be run on each node.
c1 and
c2)optistruct@host1~]$ cat config_file
-host c1 –n 2 $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] -ddmmode
-host c2 –n 2 $ALTAIR_HOME/hwsolvers/optistruct/bin/win64/optistruct_spmd [INPUTDECK] –ddmmode