Input archive
The Input archive must be a zip file. The number of jobs created depends on the data contained in the Input archive. Each created job is executed in parallel and has the resources you requested.
Solving Flux project(s)

One job will be created per Flux project and will solve every scenario defined. Hence, the projects must contain at least one scenario.
Post-processing

The created jobs will load the projects and execute the python script. Thus, the same python script is executed for all the projects.
Custom jobs

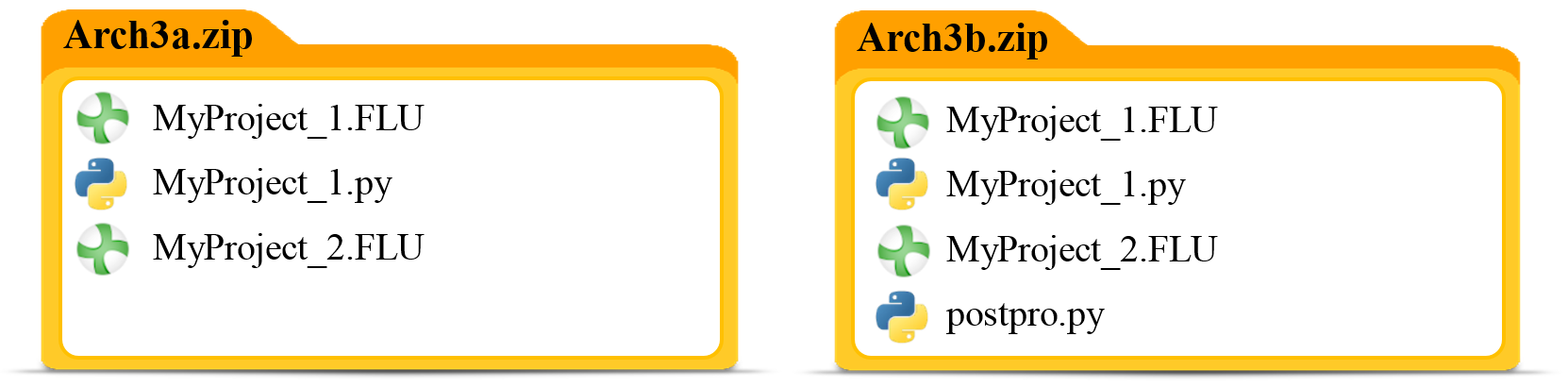
Arch3a.zip will create two jobs: one executing MyProject_1.py and the other solving MyProject_2.FLU, whereas Arch3b.zip loads MyProject_2.FLU and executes postpro.py.
Python execution jobs

will create three jobs, each executing a main*.py. The other files should not contain any Flux projects, or one of the three previous cases will be considered instead.