

|
Python Transform
A Python script can be executed as a data transformation step in the data pipeline. Specifically:
q Data is retrieved from an underlying source.
q The returned data table is translated into a Python object; specifically, a list of dictionaries.
q The Python object, and supplied Python Script are passed to an external Python process running Pyro. (Python Remote Objects) e.g., https://pypi.python.org/pypi/Pyro4/
q The external Pyro process returns a list of dictionaries
q The returned list of dictionaries is translated into a Panopticon table for visualization rendering.
|
NOTE |
· When used with streaming data sources (e.g., message bus), the Real Time Limit of a streaming data source should be set to a value longer than the time taken to perform the Python data transform. For example, if the transform operation takes 2 seconds, the Real Time Limit should be set to 2500 milliseconds. · When used for non-streaming data sources (e.g., Database), the data table Auto Refresh period should be set to a value longer than the time taken to perform the Python data transform. For example, if the transform operation takes 2 seconds, the data table Auto Refresh period should be set to 3 seconds.
|
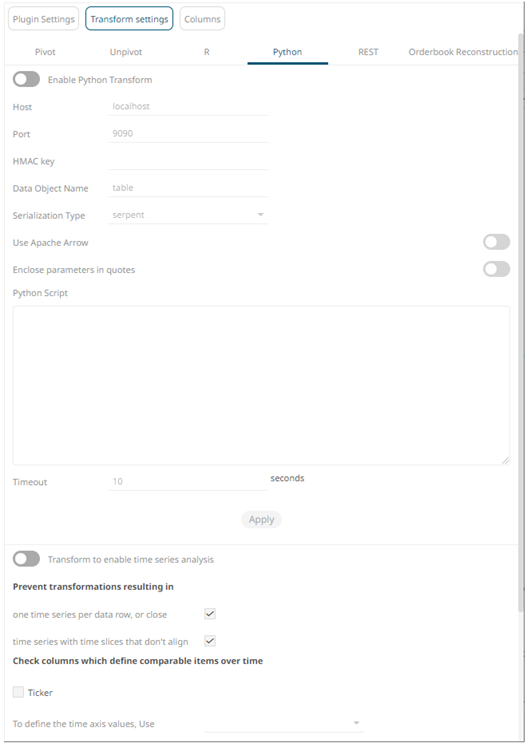
When the Python button is selected, the dialog changes to show:
Steps:
1. Tap the Enable Python Transform slider.
The
Transform Settings button and Python tab change to  and
and
 ,
respectively.
,
respectively.
2. Specify the Host and Port of the Pyro process, along with the HMAC key (Password).
3. Specify the Data Object Name. This defines the data structure (list of dictionaries) that Panopticon Visualization Server will produce, and then will be utilized by the Python script.
4. Select the Serialization Type: Serpent or Pickle
· Serpent – simple serialization library based on ast.literal_eval
· Pickle – faster serialization but less secure
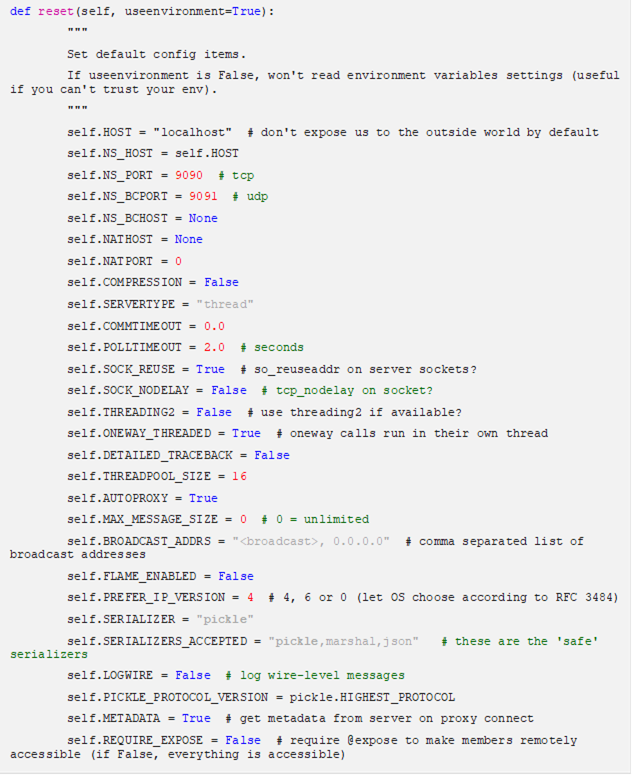
Modify the configuration.py file located in ..\Anaconda3\Lib\site-packages\Pyro4 to specify the serialization to be used.
For example, if Pickle is selected, self.SERIALIZER value should be changed to pickle and self.SERIALIZERS_ACCEPTED value should be changed to include pickle:
|
NOTE |
The Host, Port, HMAC Key, and Serialization Type fields will be hidden if their corresponding properties are set in the Panopticon.properties file.
|
5. Tap the Use Apache Arrow slider to enable fast serialization of data frames in the Python transform.
6. Enter the Python Script or load from an associated file (selected by clicking the Browse button). This returns the output list of dictionaries. Just like an underlying SQL query, the Python script itself can be parameterized.
|
NOTE |
This step will work for small and simple use cases. However, when you have several transforms, or when each transform is applied to several data tables, it is highly recommended to follow the instructions in Best Practices on Working with Python Transform in Panopticon section.
|
7. Specify whether to Enclose Parameter in Quotes.
8. The Timeout is set to 10 seconds by default to ensure that slow running Python scripts do not impact other areas of the product. You can opt to enter a new value.
9. Click  . This prepares the time series analysis.
. This prepares the time series analysis.
10. Refer to Enable Time Series Analysis for more information in enabling this feature.
11. Click  .
.