
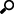

|
Kx kdb+
The Kx kdb+ connector allows connection to Kx’s kdb+ databases on a polled basis. Specifically the connector allows Panopticon Designer (Desktop) to retrieve as the results of q queries:
-
Tables
-
Lists (vectors)
-
dictionaries
-
variables
All of these data structure elements will be processed if they return primitive data types
As with relational databases, the q query can be parameterized. Typically time series conflation is achieved using the special parameters TimeWindowStart, TimeWindowEnd, and Snapshot detailed previously.
Using Kx kdb+
-
When creating a new data table, select KDB+ from the Connect to data dialog. The kdb+ Connection dialog displays.
-
Enter or set the following:
| Property |
Description |
|
Host |
Kx kdb+ host address. |
| Port |
Kx kdb+ host port. Default is 5001. |
| User Name |
The user Id that will be used to connect to Kx kdb+. |
| Password |
The password that will be used to connect to Kx kdb+. |
| Host Lookup Script
|
Key of the authentication script setting that will be retrieved from the Altair Panopticon Connector Settings. The authentication script setting will issue a shell script call passing a JSON structure containing host, port, username, and password (as below). { "host": "host", "port": 5001, "username": "username", "password": "password"}
NOTES:
Calling the script in-process from the Tomcat server running Panopticon allows automatic pick-up of the Kerberos token of the system account that started the Tomcat process.
NOTE: An exception will be thrown if the key used in the connector is not configured in the Altair Panopticon Connector Settings. |
| Timeout |
The length of time to wait for the server response. Default is 30. |
| Retry Count |
For long running queries, a query timeout can be specified to prevent the server from locking up. Default is 0. |
-
NOTE: Host, Port, User Name, Password, and Host Lookup Script can be parameterized.
-
-
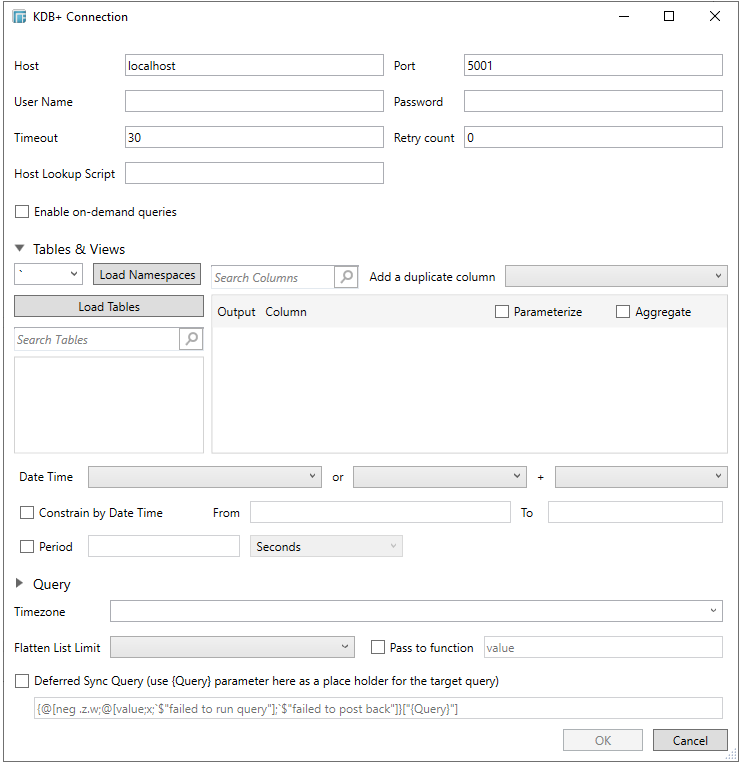
If Tables & Views is selected, the section below is enabled:
The Namespaces drop-down is an editable combo box.

You can either:
-
-
click Load Namespaces and select a namespace from the list of all root level namespaces. By default, the selected namespace will be root (backtick ‘).
-
For nested namespaces, enter them in the Namespaces box (e.g., panopticon.test) to get the tables that were created under these namespaces.
-
-
Click Load Tables. This loads the list of tables and views, which can be filtered by entering text the Search Tables search box.
-
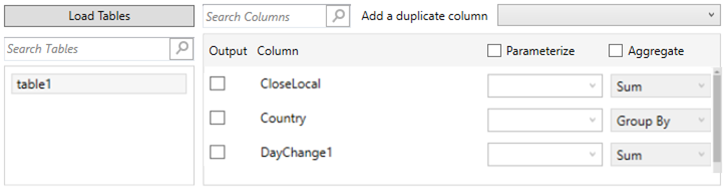
When a table or view is selected, the Search Columns listing is populated. By default, all columns are returned through SELECT * FROM TABLE.
-
Individual columns can be added by checking the corresponding Column box in the Output Columns listing.
-
If the data returned is to be aggregated, then the Aggregate box should be checked. For each selected column, the possible aggregation methods are listed including:
-
-
Text Columns: Group By
-
Date Columns: Count, Min, Max, Group By
-
Numeric Columns: Sum, Count, Min, Max, Mean, Group By
-
In addition, the qSQL query is generated. Click the Query expander button to expand the Query section.
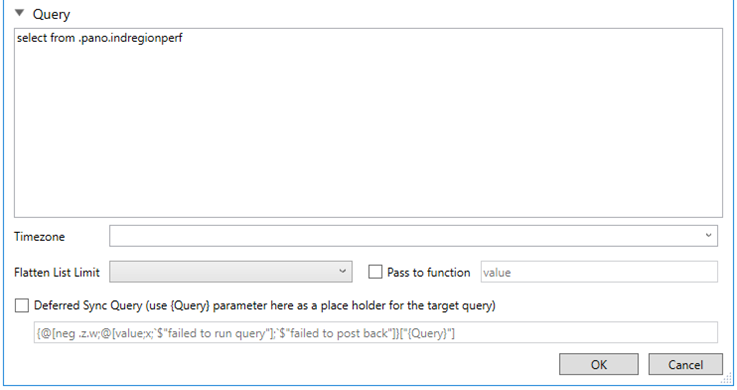
If a parameter has been defined in the data table, the qSQL can automatically be modified to refer to it.
-
Check the Parameterize checkbox, and match the parameter to the appropriate column. By default, they will be matched by name.
The appropriate qSQL Query is updated, and shown at the bottom of the dialog. This shows the default parameter value for the preview, and at run time the qSQL will be updated to whatever the parameter value is.
-
If the data is to be filtered or aggregated on Date/Times, then a valid Date/Time field needs to be selected from either a single Date/Time field, or a compound column created from a selected Date and a selected Time column.


-
The Timezone selection by default is empty. If changed to a valid time zone, check the Constrain by Date Time box, and enter From and To Date/Time constraints that are assumed to be in this time zone, and are converted to UTC for incorporation into the query.
Similarly results returned from the query are converted from UTC to the selected time zone.


If the query is to filter/constrain the results on Date/Time, the constrain sections are completed.
-
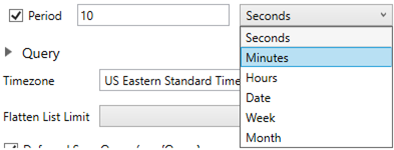
In Kx kdb+, you can modify the query to regroup the aggregated data per time units (i.e., Seconds, Minutes, Hours, Date, Week, Month). Check the Period box, enter the time duration, and select the time unit.
-
Select the Flatten List Limit.
This allows retrieval of the first ‘n’ items in the list and produce new columns in the output schema with a dot notation.
For example, if there are two nested fields (BidPrices and OfferPrices) and the flatten list limit selected is five, then the output schema will be:
BidPrices.1, BidPrices.2, BidPrices.3, BidPrices.4, BidPrices.5, OfferPrices.1, OfferPrices.2, OfferPrices.3, OfferPrices.4, OfferPrices.5
If there are less than five items in the list, then the values will be null.
NOTE: This feature is not supported in on-demand queries. Also, it only flattens numeric columns.
-
Check Pass to function box to activate a connection to a server using a proxy. Enter the value.
-
You may also define a Deferred Sync Query.
-
Click OK. The source table is returned in the Edit Data Table view, with the fields displayed in the Data Source Preview.
All fields are mapped to one of the following data types:
-
-
Text
-
Numeric (double)
-
Date/Time
-
For long running queries, a query timeout can be specified to prevent Panopticon Designer (Desktop) from locking up.
-

This results to:
-
-
The data connector either returns data, or a timeout occurs after the specified time.
-
The kdb+ instance will still try to process the query and will not stop.
-
When a q query is executed that returns a single value, a resulting table is automatically created with one column entitled Value.
If the result is a list of primitive data types, a resulting table is automatically created with one column entitled Values.
Finally if the result is a dictionary of primitive data types, a resulting table is automatically created with two columns entitled:
-
Key
-
Value