Apache Hadoop Hive
The Apache Hadoop Hive connector allows you to access the Apache Hadoop file system and supports both Hive1 and Hive2 servers.
NOTE: Starting 16.2, this connector is deprecated. The Database connector or JDBC Database connector should be used. Existing workbooks will continue to operate for this 16.2 release, but connectivity will need to be migrated for subsequent releases.
Using Apache Hadoop Hive
-
Launch the Connect to Data dialog and then select Hadoop Hive.
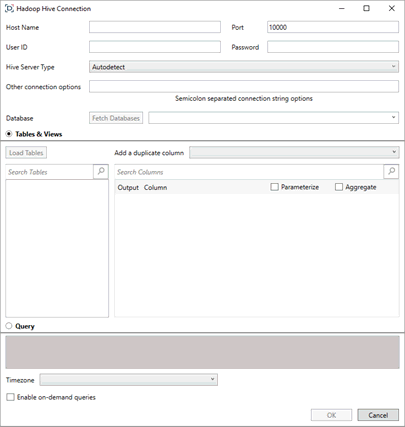
The Hadoop Hive Connection dialog displays.
-
Provide the hostname, user ID, and password required to connect to the Hive database you wish to access. If the port you wish to use is different from the default port, change the default value to the correct one.
-
From the Hive server type drop-down, choose if you want the connector to autodetect the type of server to connect to or connect to a Hive1 or Hive2 server.
-
Specify other connection options if desired, making sure to separate individual connection strings by a semi-colon.
The following table lists the connection string attributes supported by the Apache Hive driver.
|
Attribute (Short Name) |
Default |
|
ArraySize (AS) |
50000 |
|
AuthenticationMethod (AM) |
0 - User ID/Password |
|
CryptoLibName (CLN) |
Empty string |
|
CryptoProtocolVersion (CPV) |
TLSv1.2, TLSv1.1, TLSv1,SSLv3 |
|
Database (DB) |
default |
|
DataSourceName (DSN) |
None |
|
Description (n/a) |
None |
|
DefaultLongDataBuffLen (DLDBL) |
1024 |
|
EnableDescribeParam (EDP) |
0 (Disabled) |
|
EncryptionMethod (EM) |
0 (No Encryption) |
|
GSSClient (GSSC) |
native |
|
HostName (HOST) |
None |
|
HostNameInCertificate (HNIC) |
None |
|
KeepAlive (KA) |
Disabled |
|
KeyPassword (KP) |
None |
|
Keystore (KS) |
None |
|
KeystorePassword (KSP) |
None |
|
LoginTimeout (LT) |
30 |
|
LogonID (UID) |
None |
|
MaxVarcharSize (MVS) |
2147483647 |
|
PortNumber (PORT) |
10000 |
|
ProxyUser (PU) |
None |
|
RemoveColumnQualifiers (RCQ) |
0 (Disabled) |
|
ServicePrincipalName (SPN) |
None |
|
SSLLibName (SLN) |
Empty string |
|
StringDescribeType (SDT) |
12 - SQL_VARCHAR |
|
TransactionMode (TM) |
0 (No Transactions) |
|
Truststore (TS) |
None |
|
TruststorePassword (TSP) |
None |
|
UseCurrentSchema (UCS) |
0 (Disabled) |
|
UseNativeCatalogFunctions (UNCF) |
0 (Disabled) |
|
ValidateServerCertificate (VSC) |
1 (Enabled) |
|
WireProtocolVersion (WPV) |
0 - AutoDetect |
-
You can either:
-
-
click Fetch Databases to populate the drop-down list and select a database, or
-
enter the name of the database to which you want to connect.
-
-
The easiest way to select a table and/or view to load is by choosing from a set of predefined tables and views. To do so, ensure that the Tables & Views radio button is selected. If you wish to manually construct a SQL query to pull and load data, ensure that the Query button is selected. Once either a table or view or a query has been selected, the OK button at the bottom of the dialog is enabled.
-
Click Load Tables to load a list of predefined tables or views. This list can be filtered by entering an appropriate string in the Search Tables search box.
You can also add a duplicate column.
-
Select a table to display the available columns in the Search Columns list. Once a table has been selected, the Query text box is updated to reveal the results of a SELECT * FROM TABLE query. Any other selection made updates the Query text box accordingly.
-
Select the columns to add to your data table by checking their corresponding Output Column box.
-
If you wish to parameterize a specific column, check the Parameterize checkbox and, in the dropdowns that display, select the desired value.
-
If the data returned is to be aggregated, check the Aggregate checkbox.
-
The time zone of input parameters and output data is, by default, unchanged. Changing the time zone is supported by using the Timezone list box based on the assumption that data are stored in UTC time and outputs are presented in the selected time zone.
-
Check the box for Enable on-demand queries if you would like to enable this function.
-
Click OK to confirm the selection and retrieve the record set into Panopticon Designer (Desktop).
The flat record set corresponding to the executed SQL is returned from the source database and displayed in Data Prep with the database name as the title and all fields listed displayed in Data Source Preview.
-
If you wish to make changes to your fields, you may do so now and then click OK when you are finished. If you do not wish to make any changes to your data, simply select the OK button.
The data set you specified is added as a new data table.