

|
Creating Data Extract from Livy Spark
Livy is an open source REST interface for interacting with Apache Stark. It supports executing snippets of code or programs such as Scala, Python, Java, and R in a Spark context that runs locally or in Apache Hadoop YARN.
The Livy Spark connector allows you to run these codes and fetch the data in Panopticon Visualization Server.
Steps:
1. On the New Data Extract page, select LivySpark in the Connector drop-down list.
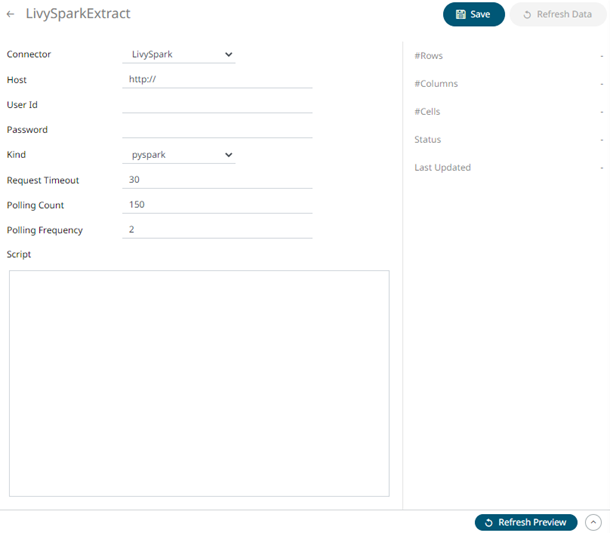
2. Follow step 3 in Livy Spark to define the connector settings.
3. Click  to save and display the details
of the data extract.
to save and display the details
of the data extract.
4. Click  then
then  to display the data preview.
to display the data preview.