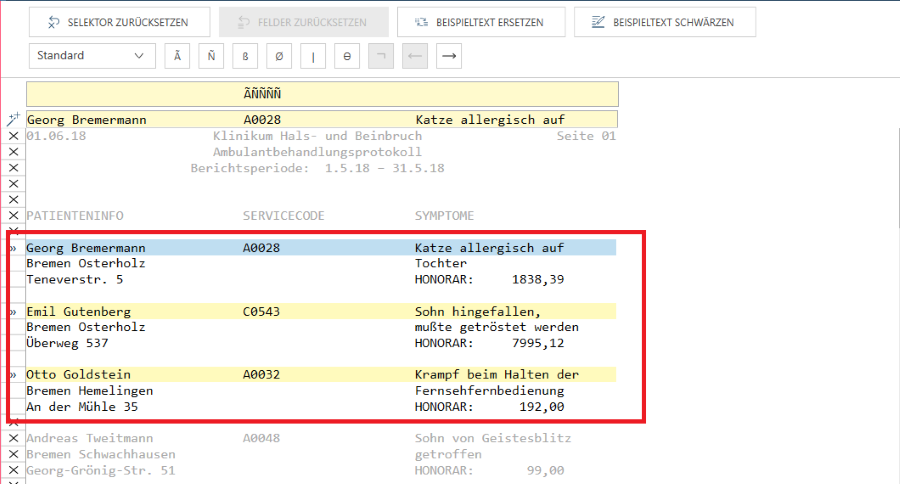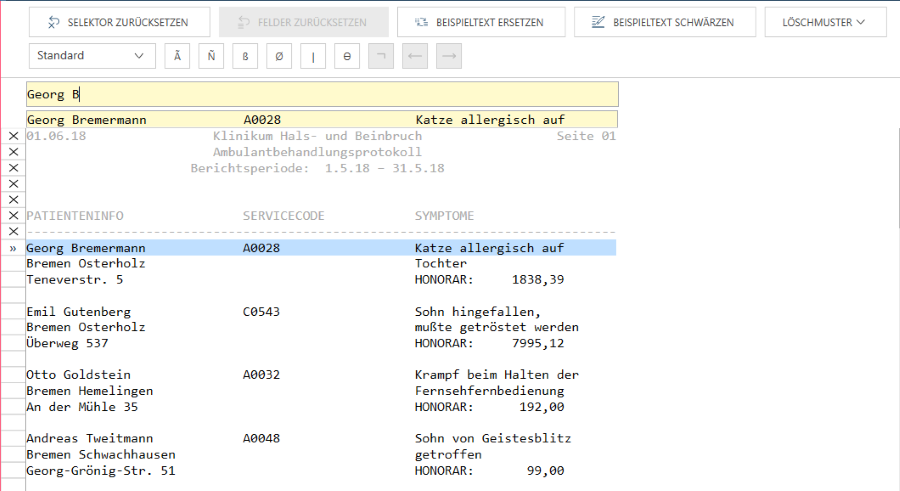
Data Prep Studio bietet eine neue Lösung für Benutzer, die Daten von einem bestimmten Bereich eines Berichts erfassen möchten, indem Start- und Endregionmuster implementiert werden.
Ein Startregionmuster markiert eine Zeile im Bericht, mit der alle anderen Selektortypen (z. B. Detail-, Anhängenselektoren) beginnen sollen, wie in der unten stehenden Abbildung dargestellt. In dieser Abbildung wurde Data Prep Studio angewiesen, die Daten in diesem Bericht von der ersten Zeile an, die mit „Michael“ markiert ist, zu erfassen. Da der Startregionmuster nur dazu gedacht ist, eine Zeile zu markieren, eignet sich ein Selektor mit exakter Übereinstimmung hier ausgezeichnet. Daten in Zeilen, die mit X markiert sind, d. h. die Zeilen oberhalb des Selektors, werden NICHT erfasst, selbst wenn Sie mit anderen Selektoren übereinstimmen, die in späteren Selektor-Sitzungen erfasst werden.
Ein Endregionmuster markiert hingegen eine Zeile im Bericht, mit der alle anderen Selektortypen (z. B. Detail-, Anhängenselektoren) enden sollen, wie in der unten stehenden Abbildung dargestellt. In dieser Abbildung wurde Data Prep Studio angewiesen, die Datenerfassung zu stoppen, wenn eine Zeile mit „Cleveland“ auftritt. Ähnlich wie mit den Startregionmustern eignen sich Selektoren mit exakter Übereinstimmung hier ausgezeichnet. Daten in Zeilen, die mit X markiert sind, d. h. die Zeilen unterhalb des Selektors, werden NICHT erfasst, selbst wenn Sie mit anderen Selektoren übereinstimmen, die in späteren Erfassungs-Sitzungen erfasst werden.
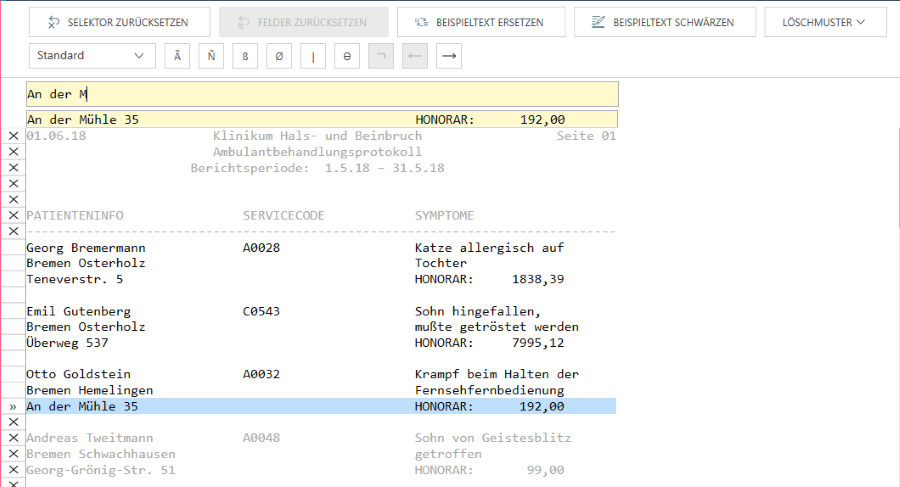
Die Abbildung unten zeigt Start- und Endregionmuster, die gleichzeitig verwendet wurden.
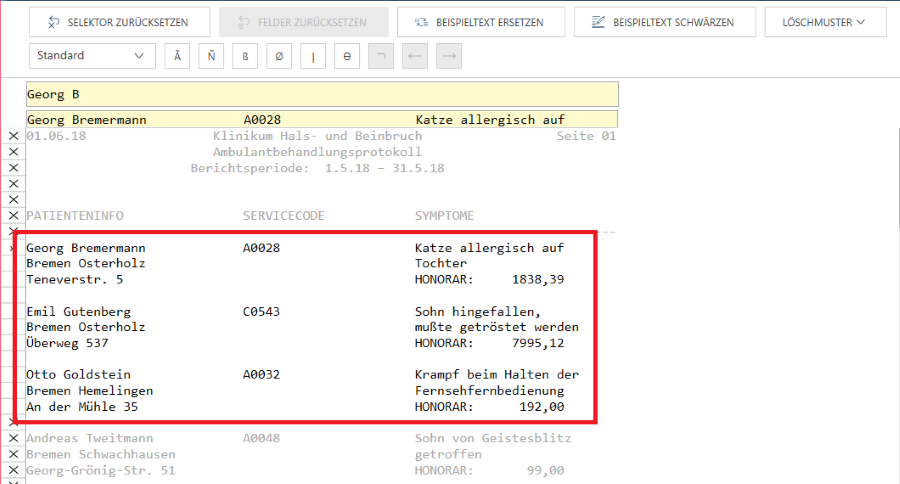
Wenn ein Muster, wie zum Beispiel ein Detailmuster, nach Angabe von Start-/Endregionmustern angegeben wird, steht nur der Bereich zwischen den Zeilen, die mit „Michael“ anfangen und mit „Cleveland“ aufhören für die Erfassung zur Verfügung.